随着互联网的发展,web应用的规模越来越大,前端再也不仅仅是写写页面特效这么简单了。前端工程变得越来越复杂,项目文件的规模也急剧扩大,手工管理静态资源的方式已经不再适用,需要一套完整的机制来实现前端的工程化。对于Hybrid应用来说,由于带宽的限制,对静态资源的管理和优化就更为重要。在mini项目的开发中,对前端资源的管理和发布进行了一些探索和实验,在这里做一个简单的总结。
基于webpack+gulp的通用方案
webpack
webpack近年来风头正劲,对类似react这种组件化开发框架来说堪称神器。webpack是一款模块管理器和打包工具,虽然也可以完成诸如代码压缩、代码转换等工作,但它的定位仍是module bundler。webpack将所有的资源都看作模块,模块之间可以定义依赖关系,由webpack对其进行整合。在实际应用中,我们只需要webpack的配置文件里定义一定的规则,剩下的工作都由webpack自动完成,我们无须关心代码整合的中间过程。
基本概念
下面我们通过一个基本的webpack配置文件来介绍webpack的几个重要概念:
webpack.config.js
module.exports = {
//入口文件配置
entry: {
index : './src/js/entry.js',
},
//输出文件配置
output: {
path: './dist'
filename: 'bundle.js'
},
module: {
//加载器
loaders: [
//.css 文件使用 style-loader 和 css-loader 来处理
{ test: /\.css$/, loader: 'style-loader!css-loader' },
//.js 文件使用 jsx-loader 来编译处理
{ test: /\.js$/, loader: 'jsx-loader?harmony' },
//.scss 文件使用 style-loader、css-loader 和 sass-loader 来编译处理
{ test: /\.scss$/, loader: 'style!css!sass?sourceMap'},
//图片文件使用 url-loader 来处理
{ test: /\.(png|jpg)$/, loader: 'url-loader'},
],
}
//插件
plugins: []
}
入口和输出
webpack根据配置文件中的entry找到工程的入口文件,加载入口文件中定义的依赖进行打包,并将最终的文件输出到output配置项定义的位置;在示例文件中,webpack会根据./src/js/entry.js生成bundle.js并输出到./dist路径下。
依赖定义
webpack兼容AMD和CommonJs风格的依赖定义。(添加了babel支持的话,也可以使用ES6的import风格,具体见后文) 你可以这样:
//AMD
define(['someModule'], function(someModule){
//dosomething
return {
output: output
};
});
也可以这样
//CommonJs
var someModule = require("someModule");
//dosomething
module.exports = {
output: output
}
};
加载器loader
loaders配置项定义了不同文件的处理器,webpack通过这些loader来处理各种类型的文件,如sass/less编译、图片转base64等。假如我们想使用ES6进行开发,只需要使用babel加载器来处理js文件即可(当然,首先要安装相应的npm包npm install babel-loader babel-preset-es2015 --save-dev):
module: {
loaders: [
{
test: /\.js$/,
exclude: /(node_modules|bower_components)/,
loader: 'babel',
query: {
presets: ['es2015']
}
}
]
}
这样就可以随心所欲使用ES6的最新特性了,比如上文提到的依赖定义可以直接使用ES6的模块机制:
//ES6 module
var someModule = import("someModule");
//dosomething
export default {output: output}
};
插件plugins
webpack有着强大的插件系统和生态圈,我们可以在plugins配置项添加需要的插件来实现定制化的需求.
一些有用的技巧和高级特性
公共代码提取
在上一节我们介绍了webpack中入口文件的概念,webpack将入口文件及其所有依赖模块打包成一个文件。对于多页面应用来说,则会存在多个入口文件(通常每个页面对应一个入口文件)。这时我们面临这样一个问题:不同入口文件的依赖模块可能存在重叠,这些重叠的依赖会被重复打包到每个入口文件的输出中,每个页面载入时都会下载一次,浪费了资源。webpack的CommonsChunkPlugin插件可以自动提取这些公共模块并将它们打包为一个独立的commons文件,从而实现多个页面共享同一份缓存,提升页面加载速度。CommonsChunkPlugin的示例配置如下:
var webpack = require('webpack');
module.exports = {
entry: {
page1: "./page1",
page2: "./page2",
},
output: {
filename: "[name].bundler.js"
},
plugins: [
new webpack.optimize.CommonsChunkPlugin("commons.js", ["page1", "page2"])
]
};
page1、page2两个模块的公共代码会被提取到commons.js,我们需要在page1.html引入commons.js和page1.bundler.js,在page2.html引入commons.js和page2.bundler.js。
样式文件单独打包
webpack将所有资源当作模块来处理,样式文件也不例外,通过require('./css/index.css')方式引入。打包后的样式文件以内联方式嵌入html页面,但有时候我们可能希望样式文件独立出来,在页面中以<link>标签引入。这时候我们需要extract-text-webpack-plugin来帮忙:
var ExtractTextPlugin = require("extract-text-webpack-plugin");
module.exports = {
//...
module: {
loaders: [
{
test: /\.css$/,
loader: ExtractTextPlugin.extract('style-loader!css-loader')
}
]
plugins: [new ExtractTextPlugin("[name].css")],
}
webpack会把模块里包含的样式文件提取出来,并命名为[模块名].css
异步加载/代码分割(CodeSplitting)
对于大型的web应用而言,把所有的代码放到一个文件的做法效率很差,特别是在加载了一些只有在特定环境下才会使用到的阻塞的代码的时候。Webpack有个功能会把你的代码分离成Chunk,后者可以按需加载。这个功能就是Code Spliiting。
Code Spliting的具体做法就是一个分离点,在分离点中依赖的模块会被打包到一起,可以异步加载。一个分离点会产生一个打包文件。
对于大型web应用尤其是单页面应用而言,按需加载/异步加载是非常必要的。假设一个单页应用有index、detail、about三个子页面(即三个路由),我们可能希望用户进入特定页面时只加载公共代码和该页面需要的代码,而不是一次性加载所有代码。webpack通过require.ensure方法提供了这一功能:
//定义一个分离点
require.ensure(dependencies, callback)
ensure保证了在所有的dependencies项加载完毕后,再执行回调 。
require.ensure(["module-a", "module-b"], function(require) {
var a = require("module-a");
// ...
});
ensure仅仅会加载dependencies数组内的依赖模块但,并不会执行,真正执行的位置是回调中的require方法。
下面我们通过一个简单示例来看看codesplitting是如何做到按需加载的:
entry.js
//index子页面加载module1
if(location.hash.indexOf('index') > -1){
//ensure保证了在所有的依赖项加载完毕后,再执行回调 。
require.ensure(['./module1.js'], function(require) {
var module = require('./module1.js');
// todo ...
});
//index子页面加载module2
}else if(location.hash.indexOf('detail') > -1){
require.ensure(['./module2.js'], function(require) {
var module = require('./module2.js');
// todo ...
});
}
...
webpack.config.js
module.exports = {
//页面入口文件配置
entry: {
index : './entry.js',
},
//入口文件输出配置
output: {
filename: '[name].bundle.js',
chunkFilename: '[chunkhash:8].chunk.js'
}
...
}
通过上述配置打包出来的文件是这样的:
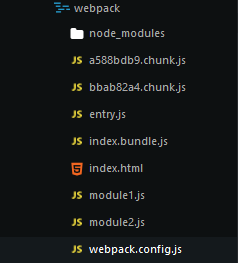
可以看到webpack将两个分离点单独打包成了两个chunk文件。打开浏览器开发工具的network查看器可以看到资源文件的加载情况:
当进入index页面时
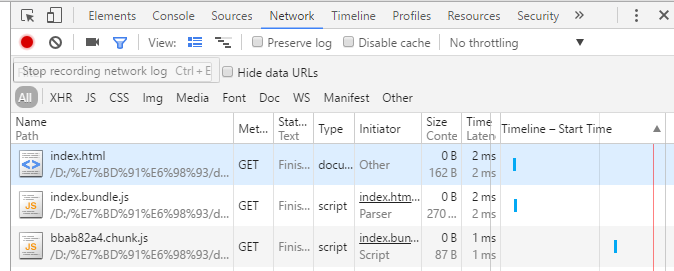
当进入detail页面时
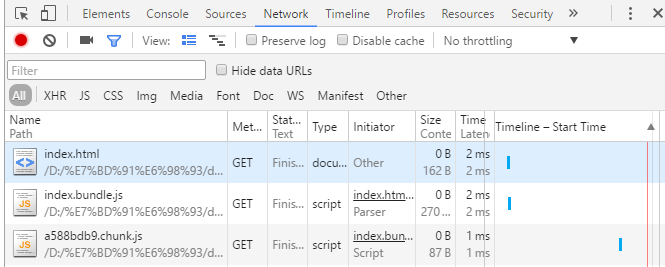
果然实现了模块按需加载!
缺点和不足
- webpack是为模块化而生的,专业处理模块一百年,但对于一些不符合模块规范的第三方库就有些力不从心了;
- webpack不暴露打包的中间过程和文件的处理细节,无法实现特殊的或定制化的需求。
e.g:- 将资源文件拷贝到输出目录
- 对资源文件进行一些文本补充、替换之类的额外处理
- 将多个文件按顺序直接合并
- 图片生成雪碧图
- 前端自动化测试
其实上面提到的这些在一定程度上并不能算是webpack的缺点,因为它的定位是module bundler,专注于对模块的处理。如果想要满足这些需求,我们需要的不仅仅是一个module bundler,而是一个前端自动化构建工具,这时候就轮到gulp出场了——
gulp
Gulp.js是一个自动化构建工具,开发者可以使用它在项目开发过程中自动执行常见任务。Gulp.js 是基于 Node.js 构建的,利用 Node.js 流的威力,你可以快速构建项目。
gulp是一款前端自动化构建工具,其定位是一个 task runner,用户可以预先定义好一系列的task,由gulp来自动执行这些task。理论上gulp 可以做到几乎所有node能做到的事情,不仅仅是用来打包js等。 gulp是一款基于流的自动化工具,它借鉴了Unix系统的管道(pipe)功能,利用node.js Stream将构建任务定义为一个个“流”,流之间通过“管道”连接,前一个流的输出即是下一个流的输入,从而将整个构建任务构造成一个“串流”。这种处理方式在思路上非常清晰自然,易于被使用者接受;更重要的是,所有的任务均在内存中进行,避免了大量的IO操作,使得gulp的构建速度很快,优于grunt等同类构建工具。
注意:gulp定义的任务是并行执行的,如果任务之间存在依赖关系则需要进行特殊处理,详情请戳这里
gulp的基本使用
下面我们通过一个基本的gulp文件来介绍gulp的使用方法:
gulpfile.js
var gulp = require('gulp');
var concat = require('gulp-concat');
var uglify = require('gulp-uglify');
//合并压缩混淆js
gulp.task('minify', function(){
return gulp.src('src/*.js')
.pipe(concat('all.js'))
.pipe(gulp.dest('dist'))
.pipe(uglify())
.pipe(gulp.dest('dist'));
});
// Watch Our Files
gulp.task('watch', function() {
gulp.watch('src/*.js', ['minify']);
});
上面的gulp文件定义了一个minify任务,对js文件进行合并和压缩混淆。需要注意的是,gulp本身只提供了一个平台,具体的合并、压缩混淆功能是由gulp-concat和gulp-uglify插件提供的。 gulp的使用非常简单,只有5个API:
- gulp.task 定义一个gulp任务
- gulp.src 指定需要处理的源文件的路径
- gulp.dest 指定处理完后文件输出的路径
- gulp.run 执行指定的gulp任务
- gulp.watch 用于监听文件变化,一旦修监听到修改就会触发指定的任务
gulp常用插件
- gulp-htmlmin 压缩 HTML
- gulp-imagemin 压缩图片(包括SVG)
- gulp-clean-css 压缩 CSS
- gulp-uglify 压缩混淆 Javascript
- gulp-concat 文件合并
- gulp-autoprefixer CSS增加前缀
- gulp-rename 修改文件名称
- gulp-webserver
- gulp-livereload 自动刷新
- gulp-sourcemaps 处理JavaScript时生成SourceMap
- gulp-jshint JavaScript 代码校验
- gulp-sass/gulp-less 编译sass/less文件
- gulp-css-spriter 生成雪碧图
- gulp-git 将gulp与git结合起来,自动化pull/push
gulp+webpack,天黑都不怕
基于gulp和webpack各自的特性,将他们结合起来使用可以出色地完成前端工程化目标:webpack作为一个module bundler,能够处理各种模块和依赖,我们利用它对js各个功能模块进行打包;gulp是一个task runner,可以流程化一切构建任务,我们利用它定义诸如文件拷贝、文件合并、图片压缩等各类任务(也包括webpack打包任务),实现构建自动化。这样,webpack和gulp可以各自完成自己最擅长的任务。 在mini项目里,我们实践了这一方案,使用webpack进行模块打包,gulp进行文件合并压缩等:
gulpfile.js
var gulp = require('gulp');
var uglify = require('gulp-uglify');
var concat = require('gulp-concat');
var minifyCSS = require('gulp-clean-css');
var webpackStream = require('webpack-stream');
var webpackConfig = require('./webpack.config.js');
var libRoot = 'src/javascript/lib/';
gulp.task('build', ['js-index', 'js-lib', 'css-lib', 'css-index']);
gulp.task('js-index', function () {
gulp.src('src/javascript/debug/index.js')
.pipe(webpackStream(webpackConfig))
.pipe(uglify())
.pipe(gulp.dest('src/javascript/dist'))
})
gulp.task('js-lib', function () {
gulp.src([libRoot+'zepto.js', libRoot+'mobilebone.js', libRoot+'frozen.js'])
.pipe(uglify())
.pipe(concat('lib.js'))
.pipe(gulp.dest('src/javascript/dist'))
});
gulp.task('css-lib', function () {
gulp.src('src/css/*.css')
.pipe(minifyCSS())
.pipe(concat('lib.css'))
.pipe(gulp.dest('src/css/dist'))
});
gulp.task('css-index', function () {
gulp.src('src/css/debug/*.css')
.pipe(minifyCSS())
.pipe(gulp.dest('src/css/dist'))
});
由于整个项目是一个规模较小的单页面应用,我们将所有的js业务模块打包成一个文件,定义为gulp的一个任务(使用gulp执行webpack任务,只需要加载webpackStream插件,并读入webpack配置文件即可);同时,将项目引入的库文件单独合并压缩为lib.js,与业务代码分离;css-lib和css-index任务则将基础样式和业务样式分别打包。由于整个项目规模不大,实际上并没有用到gulp和webpack的一些高级特性,但已经充分体验到了这一方案的强大和高效。
Hybrid架构下前端资源的加载方案
当前移动app开发领域主要有三种开发模式:Native、Webapp和Hybrid(Native+web)。由于灵活性方面的优势,Hybrid方式已经成为最普遍的开发方案。对于Hybrid应用而言,急需解决的一个问题就是web与native体验的不一致性。由于web应用的特性,每次进入web页面时需要由浏览器加载html、javascript等静态文件并执行,在这之前页面没有内容,会呈现白屏状态,严重影响用户体验。随着单页应用的盛行,不同页面之间的跳转不再需要刷新页面,已经可以实现媲美native的转场效果;但首屏加载时仍然不可避免地存在白屏问题。为了解决这一问题,争取实现首屏“秒出”的效果,越来越多的团队开始使用前端资源离线缓存方案。
前端资源离线缓存
- 将前端资源离线包与native模块一起打包在app中(或者app启动时自动下载离线包缓存在用户的sd卡)
- 用户访问web页面时直接从本地加载前端静态资源
- 当前端静态资源更新时,app从服务器下载新的离线包
由于mini项目中时间紧张,没有来得及实践这种方案的可行性。关于离线缓存这种方案,可以预见到的关键问题有:
- 离线资源何时更新?
- 离线资源如何进行更新?是否可以增量更新?
- 本地文件发出的http请求能否携带cookie信息?
- 如何解决ajax跨域问题?
- 本地化文件是否存在安全问题?
这些问题,只能在以后的工作中慢慢研究和实践了。